This is Strange... the old winworld?

After simply looking up Betaarchive in google and while on the second page of the google search I stumbled upon this...
I opened it and found the old Winworld "BetaAchive Access" page and started to click around to see what else was here...
I was surprised that most of the web pages were still here... except winboards, the almost all of the formatting and layout was gone but it was still navigatable.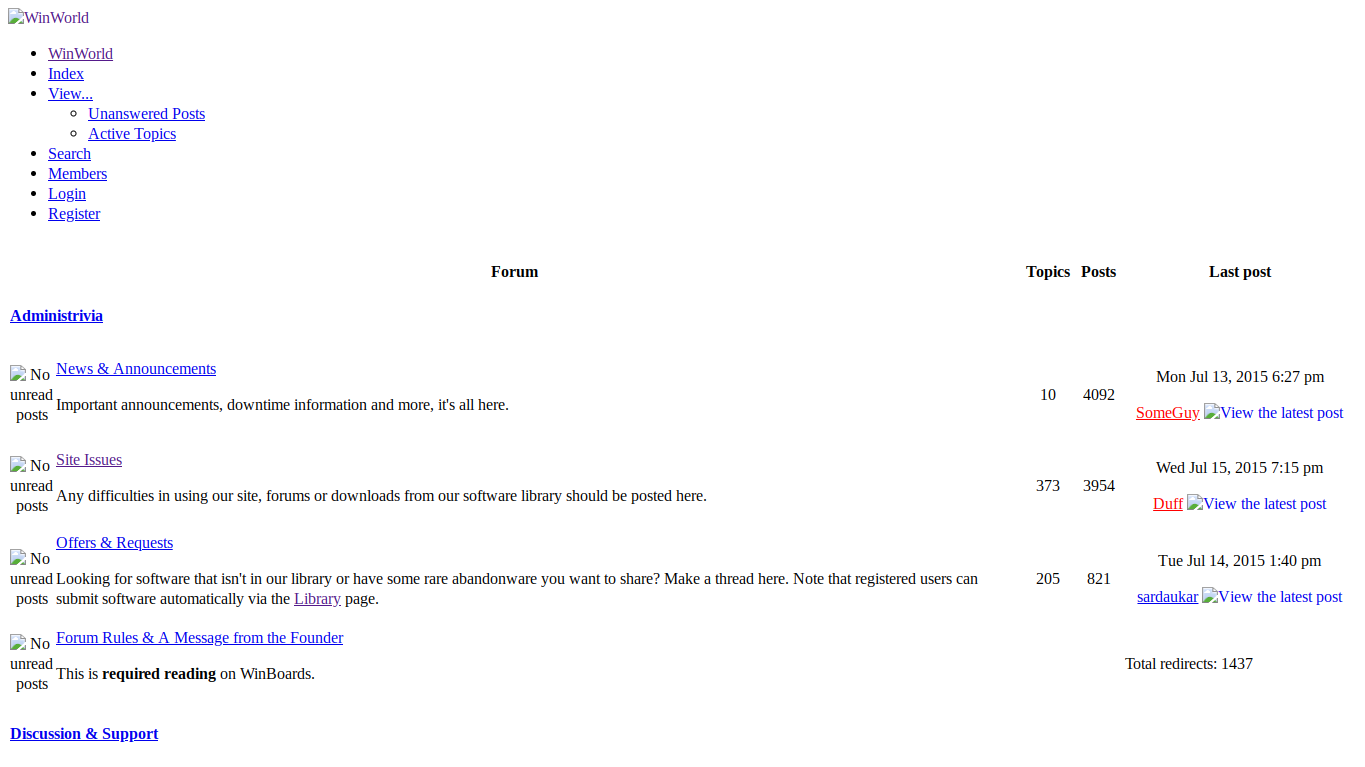
Remember this? My account didn't exist until the current winworld but I did use the site way before the update. 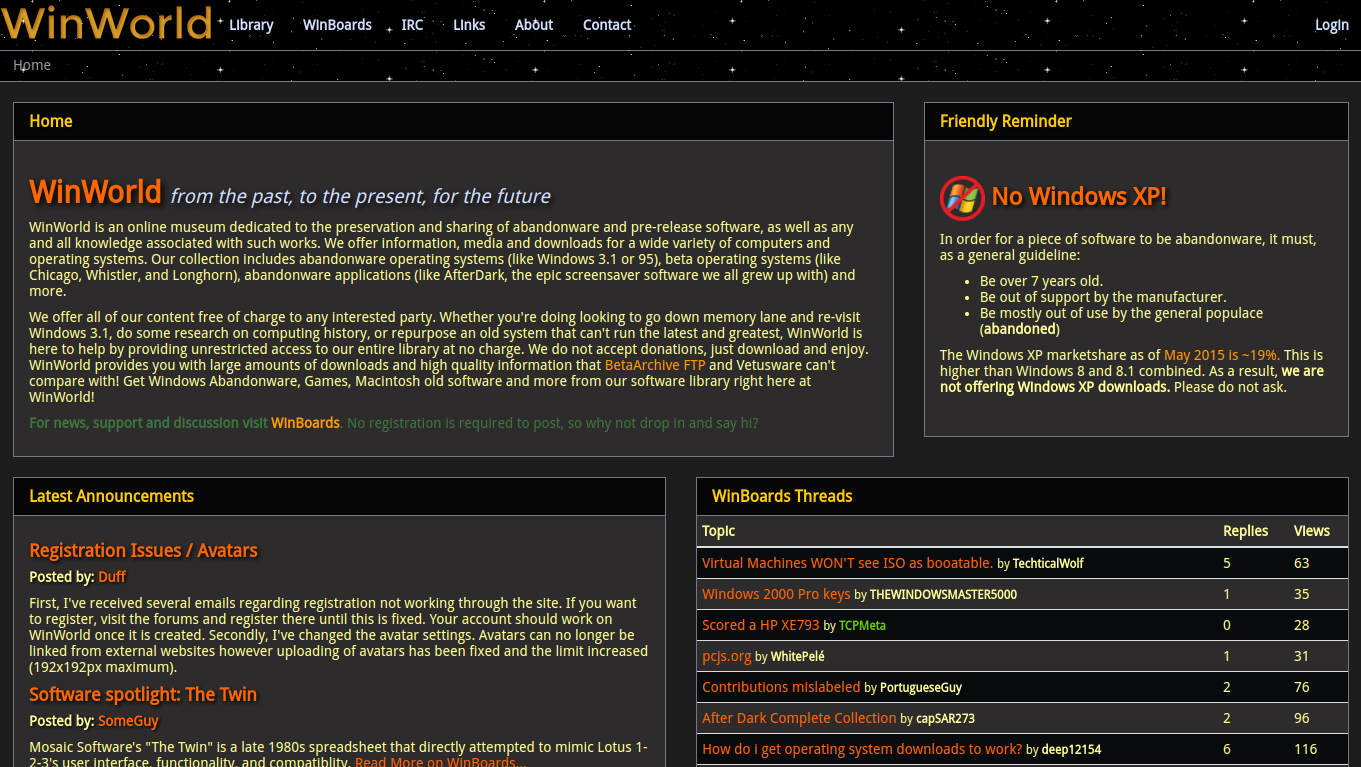
It gave me a slight sense of nostalgia seeing this... but it made me wonder why is it still open and almost fully funtional? Is it owned by any of the staff?
link to it 83.133.184.251/winworldpc.com/index.html
Comments
Interesting find, I must say. I do wonder if the staff know of this themselves.
We became aware of that site over a year ago, and it is in no way affiliated with WinWorld. Someone scraped the HTML/images and put them on a server. Since nothing actually works it's effectively pointless, the Wayback Machine accomplishes the same thing for nostalgia purposes.
I noticed that as well. The old version of WinWorldPC still works, however, when I try to download a file from there, I get the "404 Not Found" error. The forums on the old version still exist, too. Everyone there is offline, probably because most of those users got moved to the new version. But I can tell the old WinWorld I found is just a fake, because it's just different by its features compared to the real old WinWorld
Everyone is offline because it is a "dumb" copy in the sense there's no back-end, just a simple static dump; if you look at the source code you can see it was mirrored using HTTrack:
<!-- Mirrored from winworldpc.com/ by HTTrack Website Copier/3.x [XR&CO'2014], Thu, 16 Jul 2015 09:56:19 GMT -->Both the forums and the WinWorld site proper rely heavily on back-end scripting and databases that aren't publicly accessible.
I'd suggest steering clear of whatever that site is. Usually random spidered copies like that exist just to get Google hits and insert malware or such.
@SomeGuy You are right, that site file probably is a virus. Because in the URL, it started with "83.133.184.251". When I searched Google for that piece of reference, it was listed as some kind of online ransomware or something. I actually discovered this HTML file when I looked up WinWorldPC on Google Images and found the image for your old "No Windows XP" disclaimer. There I found the old site and I was like "what the what???".
I remember the old site! even the really old one when there was Cherokee as a server host.....